1月14日に開催された『第8回 XBRL勉強会』において、上場企業間の『言語処理を用いた 相関関係取得の紹介』と言うプレゼンテーションを行いました。
パワーポイントは概要のみで、多くをホワイトボードと質疑応答で話を進めましたので、こちらに補足を書きます。
■概要
これまで、インデックスを使った投資を行うにあたっては、取引所などが定義した『業種分類』や、ファンドマネージャをはじめとしたプロフェッショナルの知識・経験・そして勘でインデックスが作成されていました。また、インデックスを作成したとしても、この動きが激しい世界では企業間の関係は刻々と変化します。
そこで、定性的でありつつも企業の特徴を垣間みることができる「有価証券報告書」や「決算短信」を用い、これらを自然言語処理の技術を用いて定量化することで、企業のつながりを分析できるか否かの実験を行いました。企業分析では、あまり例がない方法であります。
■実験手順
実験は、次の手順で行いました。すべてコマンドラインベースで動作しています。プレゼン中は、技術者以外の方にもわかるようベクトルの「なす角」(cosの意味を理解するために必要)についてあわせて解説しています。
- やのしんさん開発のAPIを通じ、東証1部上場企業の2009年度中間決算短信(以下、短信)PDFをダウンロード。
このAPIを使うことで、データの取得の自動化が可能になりました。 - 短信PDFをテキストファイルへ変換。
その後に本文を解析しやすくするための準備となります。 - 各企業の短信の本文を分かち書き。
日本語は英語と違い単語の区切りがないため、専用のツールで単語ごとに「分かち書き」と言う処理が必要になります。 - 分かち書きした各企業の短信のTF、および全銘柄のIDF、RIDFを算出。
TF/IDFについては、たつをさんのエントリ『形態素解析と検索APIとTF-IDFでキーワード抽出』が詳しいです。 - 各企業の短信をすべてつきあわせ、短信間の内容の類似度(cos)を算出。
実際は7で指定する企業のみ演算すればいいのですが、今回は途中で全cos値を調べたいと思いわざわざすべて計算させました。 - RIDFを用い、各短信の代表キーワードを算出。
どんなキーワードがその短信の特徴的な単語で影響を及ぼしやすいものであるのか、わかりやすくするために抽出しました。RIDFについては、当ブログ『【シムエントリ】 代表キーワードによる検索に変わります』をご覧ください。 - 指定した企業において、cos値が0.5以上の短信を3階層までリンクしていく。
- リンク結果を図に描画する。
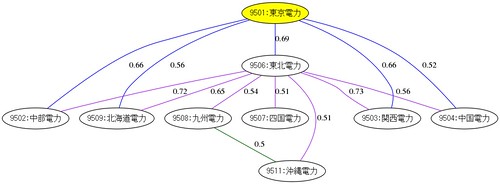
■出力データ(画像へリンク)
このような形で出力しています。紹介している企業はスライドでピックアップしているものです。
■プレゼン中いただいたお話
プレゼン中の質疑応答時間、様々なお話を頂戴しました。
・大量保有報告書や第三者割り当てのレポートを活用できないか
これらの報告をする人たちの中に、キープレーヤーがいます。そのキープレーヤーの動向をテキストマイニングで抽出できれば、より客観的に市場の動きを把握できるのでは、とのことでした。
・IFRSのメジャーカスタマー欄を参考にして取引関係をより緻密にとらえられるかもしれない
テキストマイニングばかりではなく、IFRSをはじめとしたほかのデータソースを用いて相関をよりわかりやすく(どういったつながりなのか)していく方法もある、と教えていただきました。
・XBRLとの掛け合わせについて
それぞれのタクソノミをベクトル化して類似度を測ってみたいと言う話をしたところ、リンクや米国での事例について紹介いただきました。
・一見関連性がないつながりは書いている人が一緒か同じ会社かとかがあるかもしれない
ほかにも、いろいろなご意見を頂戴しました。どうもありがとうございました。
■活用したライブラリ・ツール
多くのツールは、Ubuntuのリポジトリからダウンロードできますので、手軽にインストール可能です。
- Sun VirtualBox
- Ubuntu Linux 8.04.3 LTS Server
- Perl 5.8
- mecab + ipadic
形態素解析…分かち書きのためのツール - graphviz
相関図作成ツール - xpdf (pdftotext)
PDF関連ツール (今回はテキスト抽出のみ利用)
■参考図書
- Introduction to Information Retrieval
以前、勉強会でお世話になった教科書です。洋書ですが、情報検索に必要な知識が一通り学べます。 - 情報検索アルゴリズム
特に検索部分について解説している教科書です。上記IIR本と一緒にどうぞ。 - ゼロから学ぶ線形代数
特にドキュメント間の類似度を演算する時に利用しています。数学からしばらく離れてしまっていた場合に役立ちます。
■個人的な目的
自然言語処理と、企業分析。それぞれの分野に置いて、非常に長けた能力を持っている人や前線にたって活躍されている方がいらっしゃいます。しかし、両方を兼ね備えて活躍されている方は、あまり見受けません。正直、自分が今から一つの分野で勝負するには、かなりハードでやりきれる自信はありません。
そして、定量的分析が進んでいる企業分析に置いて、定性的データを分析しているというレポートを、私は今まであまり見たことがありませんでした(前回の勉強会で少し出た程度です)。
今回、発表する題材を決めるにあたり、自分が経験してきた自然言語処理と企業分析というあまり近くなかった分野を絡めて発表することで、何か印象を残すことができればと期待していました。それが、自分ならではのものだと思ったからです。誰かが言っていました。一つの専門の人は数多くいるけど、ある程度の能力でも二つ以上の能力を掛け合わせられる人はなかなかいない、と。
■感想
目的が達せられてよかったです。
掛け合わせると言えば聞こえはいいのですが、常識的ではないことでもありましたので勉強会内で受け入れてもらえるのか、発表まで心配でした。それも、XBRL勉強会と言うのにXBRLの話がほとんどないという…。しかし、企業分析と言うもう一つの部分について興味を持っていただくことができ、とても嬉しく思っています。また、企業の分類にテキストマイニングと言う手法があることも皆さんにお伝えできたのではと考えています。
(体調を崩していて新年会に行けなかったことだけが心残りです)
勉強会に参加されていた皆様、どうもありがとうございました!